双World架构详解:Isolated World vs Main World
· 阅读需 2 分钟

🌍 什么是"World"?
在 Chrome 扩展中,"World" 指的是 JavaScript 代码执行的上下文环境。同一个网页可以同时运行在多个独立的 JavaScript 世界中,它们之间有严格的隔离机制。
在 Chrome 扩展中,"World" 指的是 JavaScript 代码执行的上下文环境。同一个网页可以同时运行在多个独立的 JavaScript 世界中,它们之间有严格的隔离机制。
最近对浏览器扩展的开发兴趣颇大,在着手开发一个网页标记扩展,自己一直用着一款网页文档标记类的扩展工具
目前感觉非常好用就是这个叫做 Beanote 的扩展
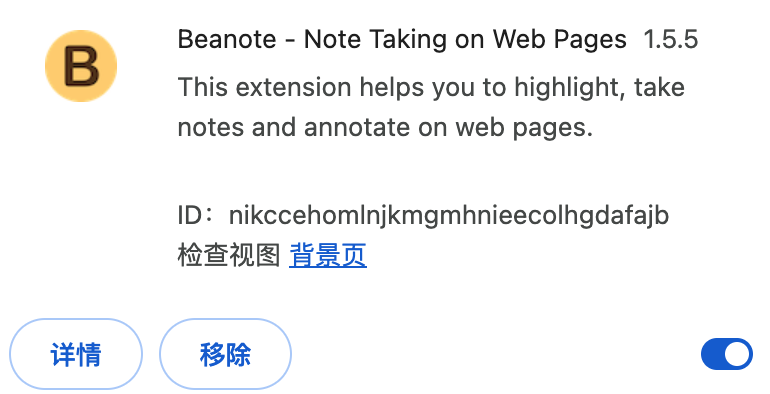
主要功能就一个,可以让你高亮标注网页中你认为重要的内容,并支持给高亮的地方做局部小的注释。
虽然功能很简单,但是感觉在阅读文档时还是挺好用的。正好自己最近的工作中也接触到了扩展的开发,
于是就趁着清明假期想自己实现一个类似功能的扩展,在写代码的过程中学到了一些 "冷门~" 的知识
当前进展如下👇
目前的功能还不完善,遇到有标签截断的情况还不能很好的处理,努力解决中💪。。
Selection 和 Range这个两个概念主要是跟鼠标在网页上的选中事件相关的,其中 Range 是一对儿代表边界点范围的对象,
其包含范围的起始点和范围的结束点。
创建一个 Range 对象跟创建其他的JS对象一样,可以通过构造函数创建
let range = new Range()
然后我们就可以通过 setStart 和 setEnd 来分别设置range对象的起始和结束范围了。
let range = new Range()
range.setStart(node, offset);
range.setEnd(node, offset);
setStart 和 setEnd 都接受两个参数,第一个参数可以是文本节点(text node) 或者是一个元素节点(element node), 这个很重要‼️因为它直接影响了第二个参数的含义.
如果是文本节点,那么offset代表的是文本中跳过字符元素的个数(是节点中的某个位置坐标)
比如说元素 <p>Hello</p>要创建一个包含 ll 的range.
<p id="p">Hello</p>
<script>
let range = new Range();
range.setStart(p.firstChild, 2);
range.setEnd(p.firstChild, 4);
// toString of a range returns its content as text
console.log(range); // ll
</script>
效果如下:

2、元素节点的情况
如果是元素节点,那么offset 代表的是其跳过子节点的个数 (这对于创建包含整个节点而不是在其文本中的某个地方截断的range很方便。)
比如说对于dom <p id="p">Example: <i>italic</i> and <b>bold</b></p>
其树状结构为:

如果要构建一个 "Example: <i>italic</i>" 范围的range 应该如何设置开始和结束点呢?
首先分析如下:

要创建的range由 <p> 的两个子节点组成,两个子节点的index 分别是 0 和 1 所以:
1、起始范围点由 p 作为父节点 0 作为起始的偏移量 range.setStart(p, 0)
2、结束范围点同样由 p 作为父节点,但是其偏移量应该是 2 ([) 坐闭右开区间,js中很多方法都是这样,不解释)range.setEnd(p, 2)
开始节点和结束节点可以是不同的节点,一个range可以跨越很多不相关的节点,只要结束节点在开始节点之后就行了
来看一个更长的跨越多个节点的range例子:

要创建这个range 应该如何设置开始节点和结束节点,及其偏移量呢?
1、首先确定开始节点和结束节点是文本节点还是元素节点,由图可知开始节点和结束节点都应该是文本节点,因为 range开始于 Example 文本的第三个字母 a 结束于 bold 文本的第三个字母 l
2、根据上一步的分析分别设置range的start和end
range.setStart(p.firstChild, 2)
range.setEnd(p.querySelector('b').firstChild, 3)

主要有以下属性:
除了setStart and setEnd 之外还有其他辅助类的方法:
所有这些方法中的node都既可以是文本节点又可以是元素节点,同样的如果是文本节点则offset代表文本字符的偏移量,如果是元素节点那么offset代表的是 跳过的子节点的个数
还有一些不常用的创建range的方法:
selectNode(node): 设置range为选中整个nodeselectNodeContents(node): 设置range为选中整个node中的内容collapse(toStart): 如果里面的 toStart 设置为true 代表end=start/start=end,也即collapse设置为true(rang崩溃 ~)cloneRange(): 克隆一个一摸一样的range当创建了 range对象之后,我们就可以利用下面这些方法来操作里面的内容了
主要是 surroundContents(node) 这个方法在设置选中文本高亮的操作中起到关键性的作用,但是其默认只能在包含完整的标签对儿的
情况下才能适用,如果一个range中的内容只包含了某个标签的起始标签 < 或者 闭合标签 </ 该方法会报错且无法执行,因此对于这
种跨标签的处理方式需要自行处理,也是目前自己在着手解决的问题之一
Range篇完~ 😩
后记:Range 返回的属性中有一个叫做:collapsed, 表示选区的起点与终点是否重叠。当 collapsed 为 true时,表示
选中区域被压缩成一个点,对于普通的元素,可能什么都看不到,如果是在可编辑的元素上,那么这个被压缩的点就变成了可以闪烁的光标!
所以,光标就是一种起始点和结束点相同的选区!
产品内部自测通过,交付用户后在用户的电脑💻上奔溃了,客户投诉产品垃圾怎么办?
定义:HTTP存档格式(HTTP Archive format,简称HAR)是一种JSON格式的存档文件格式,多用于记录网页浏览器与网站的交互过程。文件扩展名通常为.har
“HAR格式的规范定义了一个HTTP事务的存档格式,可用于网页浏览器导出加载网页时的详细性能数据 ” ——Wikipedia
如下所示:通过改扩展可以帮住你方便地记录客户电脑上一段时间发生的网络时间,通过生成的HAR包文件,方便在自己本地电脑复现!🥸(好吧,我承认这场景有点无聊🥱)
关于这个HAR扩展其实一开始我是打算纯手工拼接的方式👋 把这个har给攒出来的,头铁试了一段时间发现 臣妾做不到啊~~😭
里面涉及到的字段很多,具体可以查看这个链接🔗: http://www.softwareishard.com/blog/har-12-spec/
而且这些字段都来自页面加载过程中的不同事件,且不少有依赖关系,我粗略统计了一下至少需要监听以下这些事件👇
[
'Page.loadEventFired',
'Page.domContentEventFired',
'Page.frameStartedLoading',
'Page.frameAttached',
'Network.requestWillBeSent',
'Network.requestServedFromCache',
'Network.dataReceived',
'Network.responseReceived',
'Network.resourceChangedPriority',
'Network.loadingFinished',
'Network.loadingFailed',
...
]
有些数据的组织过程需要跨事件来攒,虽然说每个请求都有一个requestId来串起来,但是其中的拼接规则 我还是拿不准😭
于是就放弃了纯手工攒数据的方向,开始求助社区,果然在万能的npm里被我发现了这个👉:Chrome-har
看该package的简介:
“Create HAR files based on Chrome DevTools Protocol data.
Code originally extracted from Browsertime,
initial implementation inspired by Chromedriver_har.”
简介中的第一句话正是我要的,后面提到了另一个工具 Browsertime 我去看了下,很强大不过我用不到~,感兴趣的小伙伴可以去了解一下 Browsertime
npm install chrome-har 直接开搞 ⌨️
/*background.js*/
// 首先我在后台脚本的全局环境下初始化了几个变量,分别用来表示当前是否正在记录网络事件、
// 当前通信的tab页签、网页名称(这个后面给生成的har包命名用),
// 以及一个用来保存收集到的事件对象的数组,这个用来“喂” 给chrome-har 生成我需要的文件
let recording = false;
let tabId = void 0;
let tabTitle = '';
let networkEvents = []; // 收集所有的事件对象
// 定义chrome扩展的debugger事件监听函数
const debuggerEventListener = (debuggeeId, method, params) => {
networkEvents.push({method, params}); // 把监听到的事件一股脑儿全放 networkEvents 里面
}
// 监听开始的函数,需要调用chrome.debugger.attach方法将要监听的网页tabId绑定
// 并开启对 'Network.enable' 和 'Page.enable' 系列事件的监听
const startRecording = () => {
// https://developer.chrome.com/docs/extensions/reference/api/debugger?hl=zh-cn#method-attach
chrome.debugger.attach({ tabId }, '1.2', function () {
chrome.debugger.sendCommand({ tabId }, 'Network.enable', {});
chrome.debugger.sendCommand({tabId}, 'Page.enable', {}); // page事件包含时间信息,需要添加监听
});
recording = true;
}
// 停止监听函数,调用chrome.debugger.detach 方法解除对监听的网页的绑定
const stopRecording = () => {
chrome.debugger.detach({tabId}, function () {
recording = false;
})
}
// 初始化:background脚本刚加载也就是扩展刚进入工作时执行的一个给扩展icon添加一个OFF字段,
// 表示未工作
chrome.runtime.onInstalled.addListener(() => {
chrome.action.setBadgeText({
text: 'OFF' // 默认off
});
});
// 当用户点击扩展icon时候的监听函数
chrome.action.onClicked.addListener((tab) => {
tabId = tab.id; // 设置tabId
tabTitle = tab.title; // 设置tabTitle
chrome.action.getBadgeText({ tabId: tab.id }, function (preState) {
const nextState = preState === 'ON' ? 'OFF' : 'ON'; // 切换当前的工作状态的显示
chrome.action.setBadgeText({
tabId: tab.id,
text: nextState
});
if (nextState === 'ON') {
startRecording(); // 开启监听 -> attach
chrome.debugger.onEvent.addListener(debuggerEventListener); // 监听回调
} else if (nextState === 'OFF') {
stopRecording(); // 停止监听 -> detach
chrome.debugger.onEvent.removeListener(debuggerEventListener); // 移除监听回调
// 这里我们把收集到的事件做了一个过滤,去除里面的Page.frameResized事件,这个是记录开始时顶部会有一个提示扩展正在调试该页面的
// 提示信息导致页面尺寸发生变动,这个事件对于我们最终收集数据没用徒占空间,因此我们直接把它过滤出去
networkEvents = networkEvents.filter(item => item.method !== 'Page.frameResized');
// 在把收集到的事件信息发送给前台之前,做一个检查✊
if (networkEvents.length) {
// 利用chrome.tabs.sendMessage消息通信将后台收集到的数据发送给前台
chrome.tabs.sendMessage(tabId, {
type: 'Har',
harData: networkEvents,
name: tabTitle
}, null, (response) => {
if (response && response.action === 'clear') {
networkEvents = [];
}
})
} else {
alert('没有监听到任何有效数据,请重新操作。');
}
}
})
});
/*content.js 前台脚本*/
// 引入我们安装的chrome-har (注意:这是一个node包,所以我们使用commonjs的方式require引入)
const { harFromMessages } = require('chrome-har');
// 监听函数逻辑
const backgroundListener = (message, sender, sendResponse) => {
// sender.id 是扩展的id "njjdcblpajfbeljfhfgiielnhgkdmhkn"
if (message.type === 'Har') {
// 调用chrome-har包提供的 harFromMessages 方法生成 har文件
const har = harFromMessages(message.harData, {includeTextFromResponseBody: true, includeResourcesFromDiskCache: true});
if (!har.log.pages.length || !har.log.entries.length) {
alert('没有监听到任何有效数据,请重新操作。');
}
// 下面👇的操作就是生成完har包后自动下载⏬
const blob = new Blob([JSON.stringify(har)], {
type: "application/json",
});
const downloadLink = document.createElement('a');
downloadLink.href = URL.createObjectURL(blob);
downloadLink.download = `${message.name}.har`;
downloadLink.textContent = 'Download HAR';
document.body.appendChild(downloadLink);
downloadLink.click();
document.body.removeChild(downloadLink);
// 完成之后记得通知后台脚本做【清空】处理,否则下次记录网络事件会带上上一次的数据
sendResponse({
action: 'clear'
})
}
}
// 监听从后台传递过来的消息
chrome.runtime.onMessage.addListener(backgroundListener);
由于 chrome-har 是一个commonjs格式的node包,因此我们不能愉快的用vite进行构建打包只能重拾webpack,简单写个配置文件 npm run build 执行 webpack 走起!
/*webpack.config.js*/
const path = require('path');
module.exports = {
entry: '/src/content.js',
output: {
filename: 'content.js',
path: path.resolve(__dirname, 'dist'),
},
};
本以为这样就结束了,但是安装上扩展到浏览器进行测试发现,导出的har包中请求头、如参、url、时间信息...这些都有,唯独没有响应实体信息😺。。。
这个不尴尬了嘛😅,没有响应数据我看个毛啊,白折腾啊,于是我跑到了作者的github主页,去issues中试图寻找有没有类似问题,果然被我找到
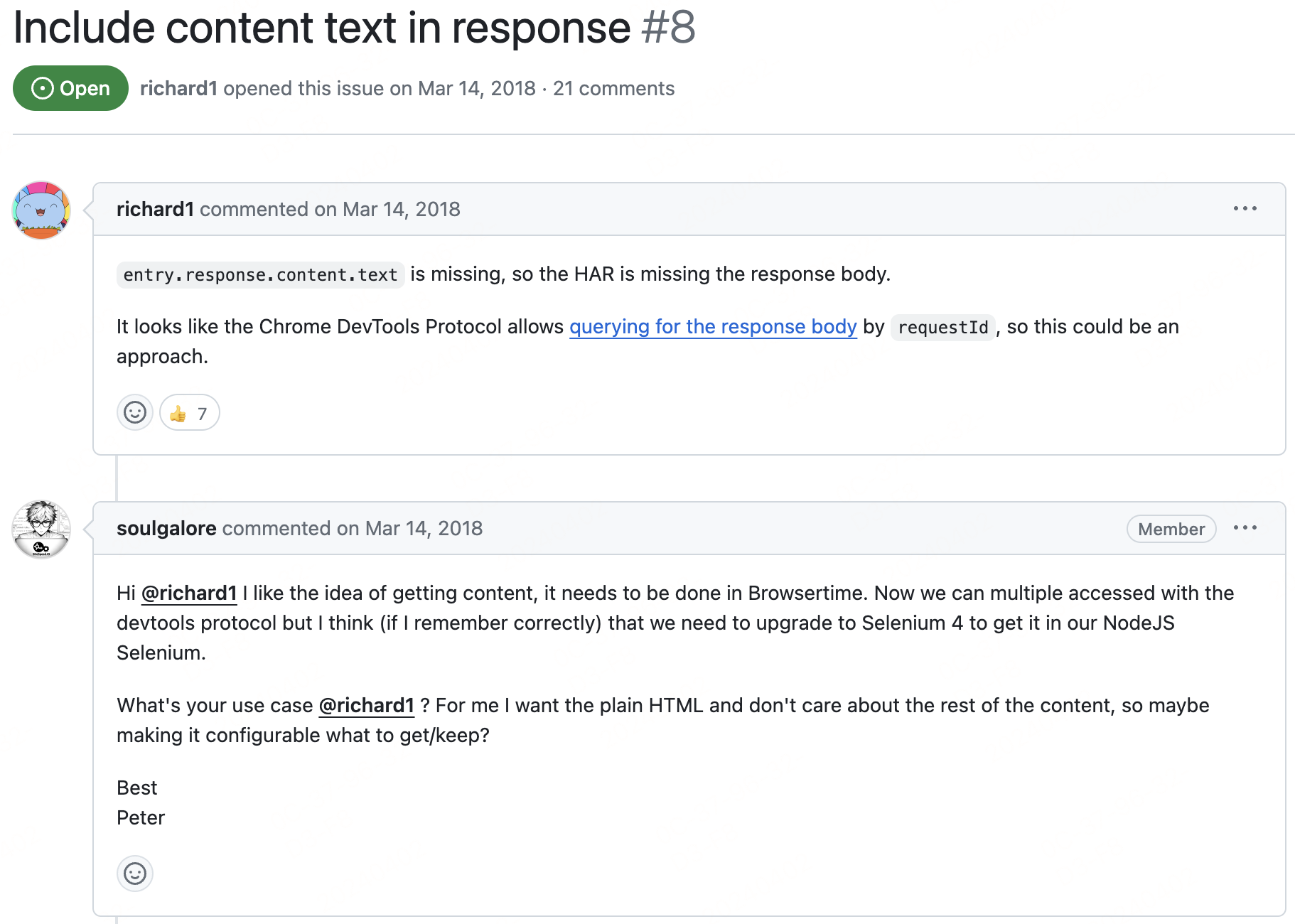
这个issue下面有很多讨论,后面作者在一系列的回复中表示,不会单独在chrome-har中实现该功能,chrome-har 将只会作为使用已有数据组装har文件的简单工具
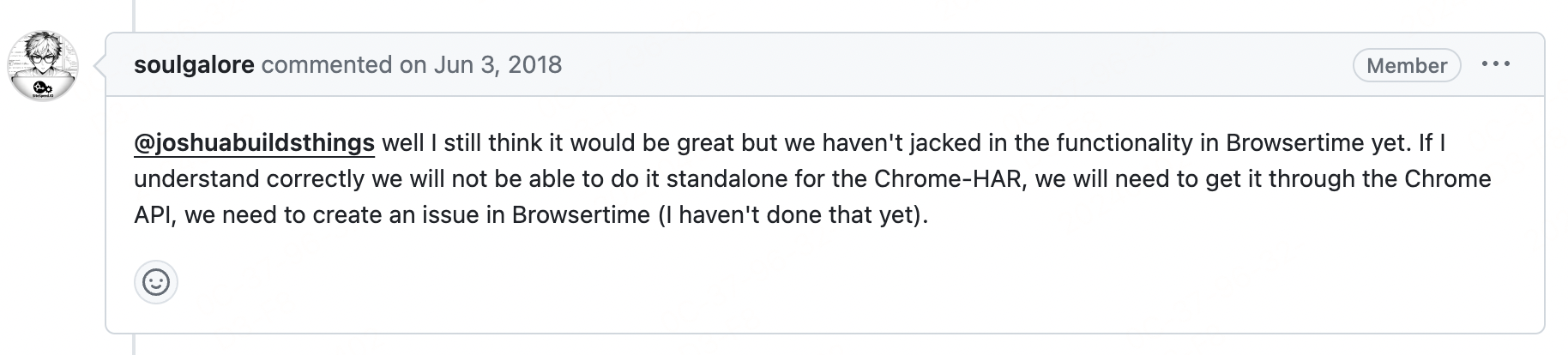
略带些许沮丧的我无奈打开了chrome-har的源码进行查看,在其中看到这样一行注释👀:

意思很明确response.body 需要我自己提供,并且给我甩出来了一个链接 🔗https://chromedevtools.github.io/devtools-protocol/tot/Network#type-Response
链接打开直接定位到了对于 Network.Response 的字段解析,从中得要想拿到response.body我需要自己通过 requestId 以异步请求的方式获取对应的 Network.Response 并从中解析出 response.body
所以我的后台脚本中需做修改
/*background.js*/
// 主要就是调整这个事件监听函数的处理逻辑,之前是把所有监听到的事件不做任何处理一股脑儿
// 直接放networkEvents里面了,现在需要做的就是对关联响应结果的事件单独做异步的请求
// 在返回的Network.Response 中解析出 response.body
const debuggerEventListener = (debuggeeId, method, params) => {
// networkEvents.push({method, params});
if (recording && debuggeeId.tabId === tabId) {
if (method !== 'Network.responseReceived' && method !== 'Network.dataReceived') {
networkEvents.push({method, params});
} else {
const requestId = params.requestId;
if (params.response) {
chrome.debugger.sendCommand({ tabId: tabId }, "Network.getResponseBody", { requestId: requestId }, function (responseBody) {
if (responseBody) {
if (responseBody.body) {
params.response.body = responseBody.body;
networkEvents.push({method, params});
} else {
networkEvents.push({method, params});
}
} else {
console.log('获取responseBody失败');
networkEvents.push({method, params});
}
});
} else {
networkEvents.push({method, params});
}
}
} else {
return;
}
}
经过一波三折的一番折腾后扩展终于可以正常工作了,撒花🎉 扩展已经发布到Chrome扩展商店,搜索 HAR Debugger 即可找到欢迎下载使用👏
这个东西最近可是太火🔥了,各种AI助手...满天飞,自己也做了一个,效果如下:
✨支持直接在PDF中划词哦~✨ 申请了专利技术😉
这里是用了 Shadowdom 封装了元素插入到文档中实现的
// 扩展的content.js
const injectShadowDom = () => {
const rootElement = document.createElement('div');
rootElement.id = 'aiAssistRoot';
// 防止重复注入
const rootDom = document.getElementById('aiAssistRoot');
rootDom && rootDom.remove();
// attachShadow to shadowHost
const shadowRoot = rootElement.attachShadow({mode: 'open'});
let reactContainer = document.createElement('div');
reactContainer.id = 'reactContainer';
shadowRoot.appendChild(reactContainer);
document.body.appendChild(rootElement);
// ⚠️注意我们的样式需要通过这种方式插入到shadowdom中
const styleNode = document.createElement('style');
const styleUrl = chrome.runtime.getURL('content.css');
fetch(styleUrl).then(res => res.text()).then(styleData => {
styleNode.textContent = styleData;
shadowRoot.appendChild(styleNode);
// 使用Antd 的 StyleProvider 将antd的样式也插入到shadowdom中
// <Scribe/> 就是我们页面上看到的划词和对话组件了
createRoot(reactContainer).render(
<StyleProvider container={shadowRoot}>
<Scribe/>
</StyleProvider>
)
})
}
injectShadowDom();
这里需要注意控制 组件拖拽的时候不要“溢出”屏幕边缘
// 拖拽限位
let x = 0;
let y = 0;
const mouseMoveHandler = (e: any) => {
const clientWidth = document.documentElement.clientWidth || document.body.clientWidth;
const clientHeight = document.documentElement.clientHeight || document.body.clientHeight;
const dx = e.clientX - x;
const dy = e.clientY - y;
// 限位,边缘不超出屏幕
if (freeBoxRef.current) {
if (freeBoxRef.current.offsetLeft + dx < 0) {
freeBoxRef.current.style.left = '0px'; // 左侧限位
} else if (freeBoxRef.current.offsetLeft + dx > clientWidth - 626) {
freeBoxRef.current.style.left = `${clientWidth - 626}px`; // 右侧限位
} else {
freeBoxRef.current.style.left = `${freeBoxRef.current.offsetLeft + dx}px`; // 左右移动范围
}
if (freeBoxRef.current.offsetTop + dy < 0) {
freeBoxRef.current.style.top = '0px'; // 顶部限位
} else if (freeBoxRef.current.offsetTop + dy > clientHeight - freeBoxRef.current.offsetHeight) {
freeBoxRef.current.style.top = clientHeight - freeBoxRef.current.offsetHeight > 0 ? `${clientHeight - freeBoxRef.current.offsetHeight}px` : '0px'; // 底部限位
} else {
freeBoxRef.current.style.top = `${freeBoxRef.current.offsetTop + dy}px`; // 上下活动范围
}
}
x = e.clientX;
y = e.clientY;
}
网页划词这部门的功能,因为我们在 content.js 中加入了 React 组件的创建 (createRoot) 所以,content.js需要单独的编译打包 单独编写 vite-content.js
/*vite-content.js*/
export default defineConfig({
root: 'src',
plugins: [
react(),
babel({
babelHelpers: 'bundled',
exclude: 'node_modules/**',
})
],
resolve: {
alias: {
'@': path.resolve(__dirname, 'src')
}
},
// ⚠️注意build的配置
build: {
outDir: '../dist',
assetsInlineLimit: 8392,
rollupOptions: {
input: {
'content': '/ext/content.js' // 打包入口设置
},
output: {
entryFileNames: '[name].js', // 打包的结果需要保持文件名一致
// ⚠️ 不可以使用 iife 的方式,iife 会把 js 和 css 都打包到一起
// format: 'iife',
// 配置打包出的其他资源,这里其实就是我们的样式代码,命名为 content.css
// 这样就可以通过 const styleUrl = chrome.runtime.getURL('content.css');
// 然后 fetch(styleUrl).then...的方式拿到我们的样式代码了
assetFileNames: 'content.[ext]'
}
},
}
})
另外我的请求也放到后台脚本 background.js 中去了,这样用户在页面的 devtools 的网络请求中就不会看到扩展的请求了 实现更好的封装和隐藏🫥,此时前台通过事件触发后台发起请求,再从后台接受返回的响应就需要一套良好的通信机制,在Chrome扩展 中主要用两种通信的方式:
1、chrome.runtime.sendMessage/chrome.tabs.sendMessage 短链接的方式
2、chrome.runtime.connect/chrome.tabs.connect 长链接的方式
短连接的话就是挤牙膏一样,我发送一下,你收到了再回复一下,如果对方不回复,你只能重新发,而长连接类似WebSocket会一直建立连接,双方可以随时互发消息。
这里开始我使用的是短链接的方式,但是发现服务端SSE推送的数据流过来的时候,需要不断的触发 sendMessage 和 onMessage 经常会出现消息错乱,同一个消息内容重复多次的bug,改成长链接的方式就好了👌。
/*content.js向background.js 发起长链接*/
const port = chrome.runtime.connect({name: "exampleName"}); // 需要传递一个带name的对象,返回一个port
...
// 之后就能利用这个port进行消息的发送和响应了
// 发送请求
port.postMessage({
type: 'gptRequest',
payload: {
params
}
});
// 接受响应
port.onMessage.addListener(msg => {
...
})
/*background.js中监听来自前台的链接请求和消息*/
chrome.runtime.onConnect.addListener(port => {
// 区分消息通道
if (port.name === 'exampleName') {
port.onMessage.addListener(msg => {
if (msg.type === 'aiRequest') {
// 可以在这里发起请求了,因为服务端返回的是流式数据,所以我采用的fetch来处理
const {params} = msg.payload;
controller = new AbortController(); // 终止信号
const {signal} = controller;
requestAi(params, signal).then(res => {
const reader = res.body?.getReader();
const decoder = new TextDecoder('utf-8');
return new ReadableStream({
start(controller) {
function push() {
reader?.read().then(({done, value}) => {
if (done) {
port.postMessage({type: 'gptResponseDown'}); // 响应结束
return;
}
let str = decoder.decode(value);
if (str.includes('error') && str.includes('code') && !str.startsWith('data: ') && !str.includes('choices')) {
// 报错
port.postMessage({type: 'gptResponseError'}); // 响应报错
controller.close();
return;
}
str = str.split('\n')
.filter((line) => line.startsWith('data: ') && line.includes('choices'))
.map((line) => JSON.parse(line.replace('data: ', '')).choices[0].delta.content).join('');
port.postMessage({
type: 'gptResponseValue',
payload: {
value: str
}
});
controller.enqueue(value);
push();
})
}
push();
}
})
})
} else if (msg.type === 'abortRequest') {
controller.abort(); // 会报一个DOMException的异常暂时无法捕获到不影响业务🤷♀️
}
})
}
})
PDF中划词能力的实现是借助了客户端封装的方法,通过在扩展中监听来自客户端的内容选中事件,并解析事件提供的参数来实现的


前端的很多状态管理工具🔧都借鉴了Flux的理念,比如大家经常听到的单向数据流的原则最初就是由Flux带入前端领域的, Flux 是由 facebook 团队推出的一种架构理念,并给出一份代码实现。
Facebook 一开始是采用传统的 MVC 范式进行系统的开发
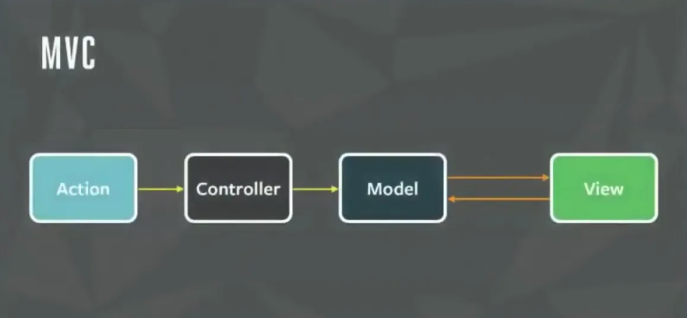
但随着业务逻辑的复杂,渐渐地发现代码里越来越难去加入新功能,很多状态耦合在了一起,对于状态的处理也耦合在了一起:
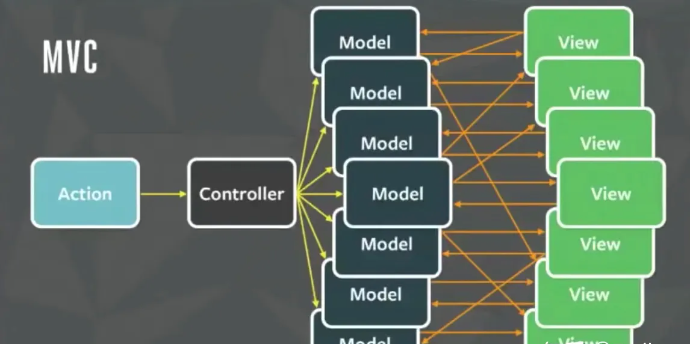
造成了 FB 团队对 MVC 吐槽最深的两个点:
由上图可以看到出基于 MVC 的数据流向就有三种:
并且三种数据流向在实际业务中还很有可能是交织在一起...
为了改善以上 MVC 在复杂应用中的缺陷,降低系统整体复杂度,FB 团队推出了 Flux 架构,结合 React 重构了他们的代码,这就是 Flux 架构诞生的原因。
其实 origin 它只是一个别名 代表的是 远程git服务器 的意思。
假设公司有一个内部gitlab或gitea搭建的服务器,地址为:http://192.168.1.100/
外网服务器上也有一个git服务器,地址为:https://git.company.com
假设你们在做一个项目叫“sixsixsix”,你是项目负责人,你叫zhangsan,现在你要给你的项目一个git仓库。
首先,你在本地搭好框架,项目文件夹是sixsixsix,然后做git的初始化和提交
cd sixsixsix
git init
git add .
git commit -m "项目起步,首次提交"
好了,现在你要推送到内部服务器,要推送到服务器,你得先添加地址,不然git怎么知道要往哪儿推送呢?😂
所以你要先在内网git服务器上添加一个仓库,并把仓库地址添加到你本地git仓库中,这样你push的时候,git才知道往哪个地址push
git remote add neiwang http://192.168.1.100/zhangsan/sixsixsix.git
远程服务器,虽然还没那么快推送,但是还是先添加一下,先把流程跑通,免得要推送的时候出问题
git remote add gongwang https://git.company.com/zhangsan/sixsixsix.git
好了,你现在添加了两个远程服务器地址了,是时候推送了
先往内部服务器推送master分支(-u neiwang用于指定向内网服务器推送)
git push -u neiwang master
后期做好之后,向公网服务器推送稳定分支(-u gongwang用于指向向公网服务器推送)
git push -u gongwang stable
是不是发现,貌似跟如下所示的(你在csdn查的)命令类似?
git push -u origin master
其实到这里你应该已经明白,neiwang、gongwang、origin这三个就是一类东西,就是用来代表“远程仓库”的,就是名称不一样而已。(git 默认生成的就叫做"origin")
事实上,推送到内网和公网的命令你还可以写成这样:
git push http://192.168.1.100/zhangsan/sixsixsix.git master
git push https://git.company.com/zhangsan/sixsixsix.git stable
其实无论neiwang、gongwang、origin,它们只是远程服务器的一个别名,否则你就要写整个地址,显然写整个地址太长太麻烦
我们平时常用的git pull就是一pull,就把同事的代码更新下来了(更新到工作目录了),但实际上,拿内网git服务器来说,如果你从内网git服务器上git pull数据,
它的操作相当于先用git fetch把数据拉到你本地项目中的.git/refs/remotes/neiwang/下边的master分支中的,如果从外网仓库拉数据,它是会先保存到.git/refs/remotes/waiwang/ 下边的stable分支中,
当然我们见过的最多的,应该还是.git/refs/remotes/origin/ 。同理,你git push的时候,数据也是先往.git/refs/remotes/neiwang/、.git/refs/remotes/waiwang/、.git/refs/remotes/origin/中的对应分支写入的
(当然写入的只是一个“引用”,具体数据都在“objects”文件夹中)
其实所谓的:neiwang、waiwang、origin,都只不过是.git/refs/remotes/下的一个文件夹名称而已, 这是git的工作原理决定的,.git/refs/remotes/下的文件夹,是跟远程仓库数据关联的,可以认为它们是远程仓库在你本地的缓存, 如果没有:neiwang、waiwang、origin这些名称,难道要把文件夹名称命名为整个仓库url那么长吗?显然这是不可能的事!
这一点还体现在你的本地仓库配置文件.git/config中:
[remote "neiwang"]
url = https://github.com/zhangsan/sixsixsix.git
fetch = +refs/heads/*:refs/remotes/neiwang/*
[remote "waiwang"]
url = https://github.com/xiebruce/sixsixsix.git
fetch = +refs/heads/*:refs/remotes/waiwang/*
[branch "master"]
remote = neiwang
merge = refs/heads/master
Use git push to push commits made on your local branch to a remote repository.
The git push command takes two arguments:
A remote name, for example, origin
A branch name, for example, master
For example:
git push <REMOTENAME> <BRANCHNAME>
As an example, you usually run $ git push origin master
to push your local changes to your online repository.
git push [remote] [local_branch]:[remote_branch] # 将本地某分支推送到远程某分支
git pull [remote] [remote_branch]:[local_brance] # 将远程某分支拉取到本地某分支
对于 git push 如果本地分支名与远程分支名相同,则可以省略冒号,例如把本地的master分支推动到远程master分支
可以使用 git push origin master 代替 git push origin master:master
对于git pull, 如果远程分支是与当前分支合并,则冒号后面的部分可以省略, 例如把远程master分支的代码合并到本地的brantest分支
可以使用 git pull origin master 代替 git pull origin master:brantest
git push origin master:master # 将本地的master分支提交到远程
git push origin master # 将本地当前分支提交到远程
git pull origin master:brantest
将远程主机origin的master分支拉取过来,与本地的brantest分支合并。
后面的冒号可以省略:
git pull origin master
表示将远程origin主机的master分支拉取过来和本地的当前分支进行合并。 (如果远程分支是与当前分支合并,则冒号后面的部分可以省略)
git push origin HEAD:master 表示将本地当前HEAD指向分支的commit提交到远程origin的master
参考:https://www.zhihu.com/question/27712995 https://blog.csdn.net/weixin_41287260/article/details/89743120 https://blog.csdn.net/weixin_44162077/article/details/124598638 https://www.runoob.com/git/git-pull.html https://www.runoob.com/git/git-push.html
本文讲述以下内容:
Q: 首先什么是文件?
A: 在计算机中文件就是存储在某种存储设备中的一段 数据,其作用就是在需要的时候可以取来使用。
在计算机中我们通常将文件分为两种,文本文件 和 二进制文件。
所谓文本文件指的就是我们可以直接通过文本编辑器,比如记事本、各类编程开发工具进行查看其内容的文件;文本文件通常都是 经过一定的字符编码的,比如最常见的ASCII编码,但其本质依旧是二进制文件, 因为在计算机看来所有的文件都是二进制的, 计算机也只认识二进制(0101...)。那我们今天说的二进制文件就是相对与文本文件而言的,二进制文件无法通过文本编辑器查看其内容, 而必须借助专门的软件程序进行打开查看,比如图片文件需要用图片查看器、音乐文件需要用到音频播放器、视频文件需要用到视频播放器等等..
文本文件是基于字符编码的文件,常见的有ASCII、Unicode等;二进制文件是基于值编码的文件,可以根据具体的应用,指定某个值是什么意思(这一过程,可以视作自定义编码,如果你定义了自己的一套编码规则,并能将数据正确的以某种形式读取出来应用的话,那么你其实是发明/创造了一种新的应用程序。)
文件的存储:在计算机的硬盘中无论是文本文件还是二进制文件都是以字节这种二进制形式存储的,当文件被读取的时候,文本文件从字节数据按照字符编码规则转换成字符数据,二进制文件比如图片会按照图像的压缩算法、色彩空间等进行图像的解码最终展示在屏幕上。
网上似乎有一个迷思说二进制文件的存取效率比文本文件高?但是却又没人能解释清楚为什么高,哪个阶段高了。在我看来二进制数据就是数据结构更加紧凑所以可能更加的节省磁盘空间,单从存储和读取的过程来看,二者并没有差别, 第一存储:文本文件需要进行文本字符到二进制编码的过程存到磁盘,而一张图片你在PS中编辑完后保存同样也有图像信息转换成二进制的转换过程。 第二读取:从磁盘读取一个文本文件的二进制数据,需要进行ASCII编码转换成文本字符展示,而打开一张图片同样有字节数据到图像信息的转换过程。
Base64编码是从二进制值到某些特定字符的编码,这些特定字符一共64个,所以称为Base64.
Q: 为什么不直接传输二进制呢,比如图片(其实也可以)既然实际传输时它们都是二进制字节流。而且使用Base64编码的过的字符串最终也是 二进制在网络上传输,那么用4/3倍带宽传输数据的Base64究竟有什么意义呢?
A: 真正的原因是为了兼容。 在网络的整个传输过程中会途径非常多的中间设备、路由器、网关、集线器、转发器...某些二进制的值,在一些硬件上比如在不同品牌的路由、老电脑上 表示的意义是不一样的,做的处理也不一样甚至在一些老的软件网络协议上也有类似的问题,但是万幸的是,Base64使用的这64个字符经过ASCII/UTF-8编码之后在绝大多数机器上,软件的行为是一致的。
ASCII编码总共128个,其中不可打印字符33个 (0 ~ 31 + 第 127),可打印字符95个 (32 ~ 126)。
| 二进制 | 十进制 | 十六进制 | 字符/缩写 | 解释 |
|---|---|---|---|---|
| 00000000 | 0 | 00 | NUL (NULL) | 空字符 |
| 00000001 | 1 | 01 | SOH (Start Of Headling) | 标题开始 |
| 00000010 | 2 | 02 | STX (Start Of Text) | 正文开始 |
| 00000011 | 3 | 03 | ETX (End Of Text) | 正文结束 |
| 00000100 | 4 | 04 | EOT (End Of Transmission) | 传输结束 |
| 00000101 | 5 | 05 | ENQ (Enquiry) | 请求 |
| 00000110 | 6 | 06 | ACK (Acknowledge) | 回应/响应/收到通知 |
| 00000111 | 7 | 07 | BEL (Bell) | 响铃 |
| 00001000 | 8 | 08 | BS (Backspace) | 退格 |
| 00001001 | 9 | 09 | HT (Horizontal Tab) | 水平制表符 |
| 00001010 | 10 | 0A | LF/NL(Line Feed/New Line) | 换行键 |
| 00001011 | 11 | 0B | VT (Vertical Tab) | 垂直制表符 |
| 00001100 | 12 | 0C | FF/NP (Form Feed/New Page) | 换页键 |
| 00001101 | 13 | 0D | CR (Carriage Return) | 回车键 |
| 00001110 | 14 | 0E | SO (Shift Out) | 不用切换 |
| 00001111 | 15 | 0F | SI (Shift In) | 启用切换 |
| 00010000 | 16 | 10 | DLE (Data Link Escape) | 数据链路转义 |
| 00010001 | 17 | 11 | DC1/XON (Device Control 1/Transmission On) | 设备控制1/传输开始 |
| 00010010 | 18 | 12 | DC2 (Device Control 2) | 设备控制2 |
| 00010011 | 19 | 13 | DC3/XOFF (Device Control 3/Transmission Off) | 设备控制3/传输中断 |
| 00010100 | 20 | 14 | DC4 (Device Control 4) | 设备控制4 |
| 00010101 | 21 | 15 | NAK (Negative Acknowledge) | 无响应/非正常响应/拒绝接收 |
| 00010110 | 22 | 16 | SYN (Synchronous Idle) | 同步空闲 |
| 00010111 | 23 | 17 | ETB (End of Transmission Block) | 传输块结束/块传输终止 |
| 00011000 | 24 | 18 | CAN (Cancel) | 取消 |
| 00011001 | 25 | 19 | EM (End of Medium) | 已到介质末端/介质存储已满/介质中断 |
| 00011010 | 26 | 1A | SUB (Substitute) | 替补/替换 |
| 00011011 | 27 | 1B | ESC (Escape) | 逃离/取消 |
| 00011100 | 28 | 1C | FS (File Separator) | 文件分割符 |
| 00011101 | 29 | 1D | GS (Group Separator) | 组分隔符/分组符 |
| 00011110 | 30 | 1E | RS (Record Separator) | 记录分离符 |
| 00011111 | 31 | 1F | US (Unit Separator) | 单元分隔符 |
| 00100000 | 32 | 20 | (Space) | 空格 |
| 00100001 | 33 | 21 | ! | |
| 00100010 | 34 | 22 | " | |
| 00100011 | 35 | 23 | # | |
| 00100100 | 36 | 24 | $ | |
| 00100101 | 37 | 25 | % | |
| 00100110 | 38 | 26 | & | |
| 00100111 | 39 | 27 | ' | |
| 00101000 | 40 | 28 | ( | |
| 00101001 | 41 | 29 | ) | |
| 00101010 | 42 | 2A | * | |
| 00101011 | 43 | 2B | + | |
| 00101100 | 44 | 2C | , | |
| 00101101 | 45 | 2D | - | |
| 00101110 | 46 | 2E | . | |
| 00101111 | 47 | 2F | / | |
| 00110000 | 48 | 30 | 0 | |
| 00110001 | 49 | 31 | 1 | |
| 00110010 | 50 | 32 | 2 | |
| 00110011 | 51 | 33 | 3 | |
| 00110100 | 52 | 34 | 4 | |
| 00110101 | 53 | 35 | 5 | |
| 00110110 | 54 | 36 | 6 | |
| 00110111 | 55 | 37 | 7 | |
| 00111000 | 56 | 38 | 8 | |
| 00111001 | 57 | 39 | 9 | |
| 00111010 | 58 | 3A | : | |
| 00111011 | 59 | 3B | ; | |
| 00111100 | 60 | 3C | < | |
| 00111101 | 61 | 3D | = | |
| 00111110 | 62 | 3E | > | |
| 00111111 | 63 | 3F | ? | |
| 01000000 | 64 | 40 | @ | |
| 01000001 | 65 | 41 | A | |
| 01000010 | 66 | 42 | B | |
| 01000011 | 67 | 43 | C | |
| 01000100 | 68 | 44 | D | |
| 01000101 | 69 | 45 | E | |
| 01000110 | 70 | 46 | F | |
| 01000111 | 71 | 47 | G | |
| 01001000 | 72 | 48 | H | |
| 01001001 | 73 | 49 | I | |
| 01001010 | 74 | 4A | J | |
| 01001011 | 75 | 4B | K | |
| 01001100 | 76 | 4C | L | |
| 01001101 | 77 | 4D | M | |
| 01001110 | 78 | 4E | N | |
| 01001111 | 79 | 4F | O | |
| 01010000 | 80 | 50 | P | |
| 01010001 | 81 | 51 | Q | |
| 01010010 | 82 | 52 | R | |
| 01010011 | 83 | 53 | S | |
| 01010100 | 84 | 54 | T | |
| 01010101 | 85 | 55 | U | |
| 01010110 | 86 | 56 | V | |
| 01010111 | 87 | 57 | W | |
| 01011000 | 88 | 58 | X | |
| 01011001 | 89 | 59 | Y | |
| 01011010 | 90 | 5A | Z | |
| 01011011 | 91 | 5B | [ | |
| 01011100 | 92 | 5C | \ | |
| 01011101 | 93 | 5D | ] | |
| 01011110 | 94 | 5E | ^ | |
| 01011111 | 95 | 5F | _ | |
| 01100000 | 96 | 60 | ` | |
| 01100001 | 97 | 61 | a | |
| 01100010 | 98 | 62 | b | |
| 01100011 | 99 | 63 | c | |
| 01100100 | 100 | 64 | d | |
| 01100101 | 101 | 65 | e | |
| 01100110 | 102 | 66 | f | |
| 01100111 | 103 | 67 | g | |
| 01101000 | 104 | 68 | h | |
| 01101001 | 105 | 69 | i | |
| 01101010 | 106 | 6A | j | |
| 01101011 | 107 | 6B | k | |
| 01101100 | 108 | 6C | l | |
| 01101101 | 109 | 6D | m | |
| 01101110 | 110 | 6E | n | |
| 01101111 | 111 | 6F | o | |
| 01110000 | 112 | 70 | p | |
| 01110001 | 113 | 71 | q | |
| 01110010 | 114 | 72 | r | |
| 01110011 | 115 | 73 | s | |
| 01110100 | 116 | 74 | t | |
| 01110101 | 117 | 75 | u | |
| 01110110 | 118 | 76 | v | |
| 01110111 | 119 | 77 | w | |
| 01111000 | 120 | 78 | x | |
| 01111001 | 121 | 79 | y | |
| 01111010 | 122 | 7A | z | |
| 01111011 | 123 | 7B | ||
| 01111100 | 124 | 7C | | | |
| 01111101 | 125 | 7D | } | |
| 01111110 | 126 | 7E | ~ | |
| 01111111 | 127 | 7F | DEL (Delete) | 删除 |
1、Post请求简单表单数据:Content-Type: application/x-www-form-urlencoded
通常被用于HTML表单提交,数据会被编码成键值对的形式
2、Post请求,JSON数据:Content-Type: application/json
当通过 POST 请求发送 JSON 格式的数据时,应该使用这个 Content-Type。这在现代 Web 开发中很常见,特别是与 RESTful API 一起使用
3、POST请求,文件上传:Content-Type: application/form-data
用于通过 POST 请求上传文件。常用于表单中包含文件上传的场景
4、POST请求,纯文本数据:Content-Type: text/plain
用于发送纯文本数据。
5、Get请求,一般不包含请求体,但是如果包含了一般使用 Content-Type: application/x-www-form-urlencoded 或者 Content-Type: text/plain
6、XML 数据:Content-Type: application/xml, 当需要发送或接收 XML 数据时使用.
Content-Type 既可以出现在请求头中,也可以出现在响应头中。在 HTTP 协议中,Content-Type 是用来指示实体正文的媒体类型的标头字段。
因此,Content-Type 是一个常见的请求头和响应头字段,用于确保发送和接收的数据以正确的格式进行解析。在请求头中,它告诉服务器请求正文的格式,而在响应头中,它告诉客户端返回数据的格式。
responseType 是Fetch API 中请求配置对象的一个属性,因此他是请求头的一部分,用于指定服务器响应 的数据类型。axios 是一个基于Promise的http客户端库,它在使用上很类似于Fetch API,并且也提供了类似的 配置项其中包括responseType.
可以通过配置responseType来告诉浏览器希望以什么样的数据类型来处理服务器响应。以下是一些常见的responseType值
1、responseType: 'text' 将响应解析为文本字符串
2、responseType: 'json' 将响应解析为JSON对象
3、responseType: 'blob' 将响应解析为二进制数据(Blob对象)
4、responseType: 'arraybuffer' 将响应解析为二进制对象(ArrayBuffer对象)
5、responseType: 'document' 将响应解析为XML文档(可以是XML、HTML等)
6、responseType: 'stream' 用于将响应数据以Node.js 可读流的形式返回。这种形式对于处理大型响应数据或实时数据流非常有用!
FileReader 对象允许Web应用程序异步读取存储在用户计算机上的文件(或原始数据缓存区)的内容,使用File 或者Blob 对象指定要读取的文件或数据。
其中 File 对象可以是来自用户在一个input元素上选择文件后返回的FileList对象,也可以来自拖放操作生成的 DataTransfer对象,还可以是来自在一个HTMLCanvasElement上执行mozGetAsFile()方法后返回结果。
File对象可以看作一种特殊的Blob对象. Blob是File的父类。
1、FileReader.readAsArrayBuffer(): 开始读取指定的 Blob中的内容,一旦完成,result 属性中保存的将是被读取文件的 ArrayBuffer 数据对象。
2、FileReader.readAsDataURL(): 开始读取指定的Blob中的内容。一旦完成,result属性中将包含一个data: URL 格式的 Base64 字符串以表示所读取文件的内容。
3、FileReader.readAsText(): 开始读取指定的Blob中的内容。一旦完成,result属性中将包含一个字符串以表示所读取的文件内容。
当我们需要读取一个文件的时候,如果是文本文件我们就可以通过 let fr = new FileReader(); fr.readAsText('文件') 方法来读取文件内容; 而当文件是一个二进制文件的时候,我们就可以通过fr.readAsArrayBuffer('文件')来读取文件内容。
// 读取文本文件:
// 创建 FileReader 对象
const reader = new FileReader();
// 为 FileReader 设置 onload 事件处理程序
reader.onload = function(event) {
// event.target.result 包含文件的文本内容
console.log(event.target.result);
};
// 读取文本文件
const fileInput = document.getElementById('fileInput'); // 假设有一个 input 元素用于选择文件
const selectedFile = fileInput.files[0];
reader.readAsText(selectedFile);
// 读取图像文件并显示:
const reader = new FileReader();
reader.onload = function(event) {
// event.target.result 包含图像文件的 data URL
const imgElement = document.getElementById('imageElement'); // 假设有一个 img 元素用于显示图像
imgElement.src = event.target.result;
};
const fileInput = document.getElementById('fileInput'); // 假设有一个 input 元素用于选择文件
const selectedFile = fileInput.files[0];
reader.readAsDataURL(selectedFile);
// 读取二进制文件(例如,ArrayBuffer):
const reader = new FileReader();
reader.onload = function(event) {
// event.target.result 包含二进制文件的 ArrayBuffer
const arrayBuffer = event.target.result;
// 处理 ArrayBuffer
};
const fileInput = document.getElementById('fileInput'); // 假设有一个 input 元素用于选择文件
const selectedFile = fileInput.files[0];
reader.readAsArrayBuffer(selectedFile);
需要注意的是,由于文件读取是异步的,因此 FileReader 使用事件处理程序(例如 onload)来捕获读取完成后的结果。
参考:https://betterprogramming.pub/what-are-cjs-amd-umd-esm-system-and-iife-3633a112db62
现代JS开发会被打包器打包📦成各种格式,不同的格式分别可以运行在不同的环境之中,主要的打包格式和其适用范围如下
<script type=module> 的现代浏览器<script> 标签引入CommonJS是Node及其生态环境中使用的格式类型,被广泛的应用于服务端。CommonJS可以通过require()方法和module.exports命令来识别。 require()方法用于导入一个node模块,而module.exports是模块被require()方法导入时返回的对象。
CommonJS最初就是设计用来在服务端使用的,所以它的API自然地都是同步,也就是说CommonJS的模块导入顺序是按书写顺序导入的。
👇下面是一个用roll-up生成的CommonJS格式的文件📃
'use strict';
Object.defineProperty(exports, '__esModule', { value: true });
/**
* Increase the current total value
* @param {number} total The current total value
* @param {number} value The new value to be added
* @returns {number} The new total value
*/
const increase = (total, value) => total + value;
/**
* Decrease the current total value
* @param {number} total The current total value
* @param {number} value The new value to be subtracted
* @returns {number} The new total value
*/
const decrease = (total, value) => total - value;
let others = {
a: 1,
b: 2,
c: () => 3,
};
const e = 5;
/**
* This is the main file
*/
function multiply(total, value) {
return total * value;
}
function power(total, value) {
return total ** value;
}
let total = others.a;
total = increase(total, 10);
total = increase(total, 20);
total = decrease(total, 5);
total = multiply(total, e);
console.log(`Total is ${total}`);
exports.power = power;
👆上面的文件直接在浏览器中执行会报错 exports is not defined
可以通过添加如下代码来修复上面的报错
<script>
const exports = {};
</script>
UMD被设计既能在服务器端运行也能在浏览器中运行,其内部使用AMD格式作为基础,并添加了很多特殊的 外壳代码 用来处理CommonJS的兼容。
然而,兼容性增加了一些复杂性,也使得读写变得复杂。
官方出品的模块化标准。Since the version of ^12.20.0 || ^14.13.1 || >=16.0.0, Node starts to support ESM. ESM gains popularity to be used for both clients and servers.
~ Node支持ESM后ESM越来越受欢迎👏,可以同时在客户端和服务端开发运行。
esm的 import 指令可以将一个es模块导入当前的作用域,而动态的 import() 方法在ES2020标准中支持; export 指令可以将模块暴露给其他模块供引入。
自执行函数格式适用于直接通过 <script> 标签引入代码的方式,它将代码放入函数的命名空间中避免了命名冲突。
cjs模块是对象,输入时必须查找对象的属性;esm模块不是对象,而是通过export命令 显示地指定对外输出的代码,再通过 import命令 输入。
在node执行一个文件的时候,会自动给这个文件内生成一个module对象和一个exports对象,而module对象又一个exports属性, 它们之间的关系如下图,默认都是指向同一块内存的:
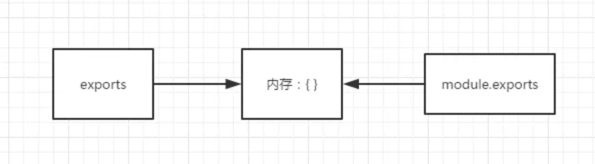 看代码:
看代码:
//example.js
let a = 100;
console.log(module.exports); //打印出结果为:{}
console.log(exports); //打印出结果为:{}
console.log(exports === module.exports); // 输出结果为true
module.exports.a = 100;
exports.a = 200; // 这里exports _辛苦劳作_ 帮 module.exports 将属性_a_的内容给改成200
exports = '指向其他内存区'; // 注意⚠️:这里将exports重新赋值里,exports将不再跟module.exports指向同一内存区域,后面exports的一系列属性设置将不再影响module.exports
...
//test.js
let a = require('/example'); // 在test.js中通过 `require()` 方法引入example
console.log(a) // 打印为 {a : 200}; // 证明在node中 `require()` 方法引入的内容是module.exports对象而不是exports!!
exports对象只是为了让你在给模块定义属性的时候,可以少打几个字母,直接用exports.a = 123, exports.b = 456 ...就行了不用麻烦的带着module.exports.a = xxxx 但是千万不要把exports直接赋值给其他值哦~ 一旦写了 exports = xxx exports和 module.exports之间的联系就断了~
esm的模块功能主要由两个命令组成:export 和 import
再次提醒,esm中的 export 和 import 是命令(或者叫关键字😝)不是方法。
export命令用于规定模块的对外接口,import命令用于输入其他模块提供的功能。在esm中一个文件就是一个独立的模块,在文件模块内部所有的变量,外部
是无法获取的,如果希望外部能够读取内部的某个变量,就必须显示的使用 export 关键字输出该变量。
可以向下面这样👇
写法一:用三个export命令对外输出三个变量
// profile.js
export let firstName = 'Michael';
export let lastName = 'Jackson';
export let year = 1958;
写法二:使用大括号指定所要输出的一组变量👍
// profile.js
let firstName = 'Michael';
let lastName = 'Jackson';
let year = 1958;
export {firstName, lastName, year};
第二种与前一种写法(直接放置在let语句前)是等价的,但是应该优先考虑使用这种写法。因为这样就可以在脚本尾部,一眼看清楚输出了哪些变量。
通常情况下,export输出的变量就是本来的名字,但是可以使用as关键字重命名。像下面这样👇
function v1() { ... }
function v2() { ... }
export {
v1 as streamV1,
v2 as streamV2,
v2 as streamLatestVersion
};
需要特别注意的是,export命令规定的是对外的接口,必须与模块内部的变量建立一一对应关系。
👇下面的两种写法都是错的❌
// 报错
export 1;
// 报错
let m = 1;
export m;
上面两种写法都会报错,因为没有提供对外的接口。第一种写法直接输出 1,第二种写法通过变量m,还是直接输出 1。1只是一个值,不是接口。正确的写法是下面这样。
// 写法一
export let m = 1;
// 写法二
let m = 1;
export {m};
// 写法三
let n = 1;
export {n as m};
上面三种写法都是正确的,规定了对外的接口m。其他脚本可以通过这个接口,取到值1。它们的实质是,在接口名与模块内部变量之间,建立了一一对应的关系。
同样的,function和class的输出,也必须遵守这样的写法。
目前,export 命令能够对外输出的就是三种接口:函数(Functions), 类(Classes),var、let、const 声明的变量(Variables)。
另外,export语句输出的接口,与其对应的值是动态绑定关系,即通过该接口,可以取到模块内部实时的值。
export let foo = 'bar';
setTimeout(() => foo = 'baz', 500);
上面代码输出变量foo,值为bar,500 毫秒之后变成baz。
这一点与 CommonJS 规范完全不同。CommonJS 模块输出的是值的缓存,不存在动态更新.
使用export命令定义了模块的对外接口以后,其他 JS 文件就可以通过import命令加载这个模块
// main.js
import { firstName, lastName, year } from './profile.js';
function setName(element) {
element.textContent = firstName + ' ' + lastName;
}
上面代码的import命令,用于加载profile.js文件,并从中输入变量。import命令接受一对大括号,里面指定要从其他模块导入的变量名。大括号里面的变量名,必须与被导入模块(profile.js)对外接口的名称相同。
import命令输入的变量都是只读的,因为它的本质是输入接口。也就是说,不允许在加载模块的脚本里面,改写接口。
import {a} from './xxx.js'
a = {}; // Syntax Error : 'a' is read-only;
上面代码中,脚本加载了变量a,对其重新赋值就会报错,因为a是一个只读的接口。但是,如果a是一个对象,改写a的属性是允许的。
import {a} from './xxx.js'
a.foo = 'hello'; // 合法操作
上面代码中,a的属性可以成功改写,并且其他模块也可以读到改写后的值。不过,这种写法很难查错,建议凡是输入的变量,都当作完全只读,不要轻易改变它的属性。
import语句会执行所加载的模块,因此可以有下面的写法。
import 'lodash';
上面代码仅仅执行lodash模块,但是不输入任何值。
注意⚠️:上面这种情况很多人分不清,网上也很多人理解成 export default的情况,import 'lodash 和 import lodash from 'lodash' 、import _ from 'lodash'
是完全不同的意思,后者很好理解,就是将lodash库引入进来并赋值为lodash _ 变量,而 import 'lodash 仅仅只是执行了loadash模块,并没有输入任何值!
网上这里有个例子: https://segmentfault.com/q/1010000006229052
 和 css 里 @import xxx.css 类似的功能,
和 css 里 @import xxx.css 类似的功能,import lodash 只是把 lodash 这个模块当做静态文件在编译阶段引入而已。。。。
另:ES6 想要 import 一个模块中的变量等内容必须对其做模块解构,否则只会执行代码而没有任何导入的内容。这个道理跟 Node.js 中的模块没有 export 内容就 require 就只会执行代码不会导入内容是一个道理
目前阶段,通过 Babel 转码,CommonJS 模块的require命令和 ES6 模块的import命令,可以写在同一个模块里面,但是最好不要这样做。因为import在静态解析阶段执行,所以它是一个模块之中最早执行的。下面的代码可能不会得到预期结果。
require('core-js/modules/es6.symbol');
require('core-js/modules/es6.promise');
import React from 'React';
使用import命令的时候,用户需要知道所要加载的变量名或函数名,否则无法加载。但是,用户肯定希望快速上手,未必愿意阅读文档,去了解模块有哪些属性和方法。 为了给用户提供方便,让他们不用阅读文档就能加载模块,就要用到export default命令,为模块指定默认输出。
// export-default.js
export default function () {
console.log('foo');
}
上面代码是一个模块文件export-default.js,它的默认输出是一个函数。
其他模块加载该模块时,import命令可以为该匿名函数指定任意名字。
// import-default.js
import customName from './export-default';
customName(); // 'foo'
上面代码的import命令,可以用任意名称指向export-default.js输出的方法,这时就不需要知道原模块输出的函数名。需要注意的是,这时import命令后面,不使用大括号。
上一节的最后一个例子中
import React from 'React';
import React 没有使用打括号,就是因为React库内部使用 export default 指定了默认导出接口。
export default 命令用于指定模块的默认输出。显然,一个模块只能有一个默认输出,因此export default命令只能使用一次。所以,import命令后面才不用加大括号,因为只可能唯一对应export default命令。
本质上,export default 就是输出一个叫做default的变量或方法,然后系统允许你为它取任意名字。所以,下面的写法是有效的。
// modules.js
function add(x, y) {
return x * y;
}
export {add as default};
// 等同于
// export default add;
// app.js
import { default as foo } from 'modules';
// 等同于
// import foo from 'modules';
有了export default命令,输入模块时就非常直观了,以输入 lodash 模块为例。
import _ from 'lodash';
如果想在一条import语句中,同时输入默认方法和其他接口,可以写成下面这样。
import _, { each, forEach } from 'lodash';
对应上面代码的export语句如下:
export default function (obj) {
// ···
}
export function each(obj, iterator, context) {
// ···
}
export { each as forEach };