http 1 2 3
http2
优化
1、头部压缩 http1.1报文的Header中一般都会携带User Agent Cookie Accept Server 等许多固定的头字段, 多达几百甚至上千字节,但是body却经常只有几十字节(比如Get请求、204/301/304等响应)成了大头儿子。 Http2 把头部压缩 作为性能改进的一个中重点,优化的方式依旧是“压缩”。不过没有使用传统的压缩算法,而是专门开发了 Hpack 算法,在客户端和服务器端建立字典,用索引表示重复的字符串,使用哈夫曼编码来压缩整数和字符串,达到50%~90%的高压缩率。
2、二进制格式
http2不再使用明文的ASCII码,而是向下层的TCP/IP协议靠拢,全面采用二进制格式。体积小,速度快!将原来Header + Body的消息打散为 多个小片的二进制帧,用HEADERS 帧放头数据,用DATA 帧存放实体数据。----化整为零的思路。这种做法有点像是“Chunked”分块编码的方式(参见第 16 讲),也是“化整为零”的思路,但 HTTP/2 数据分帧后“Header+Body”的报文结构就完全消失了,协议看到的只是一个个的“碎片”。
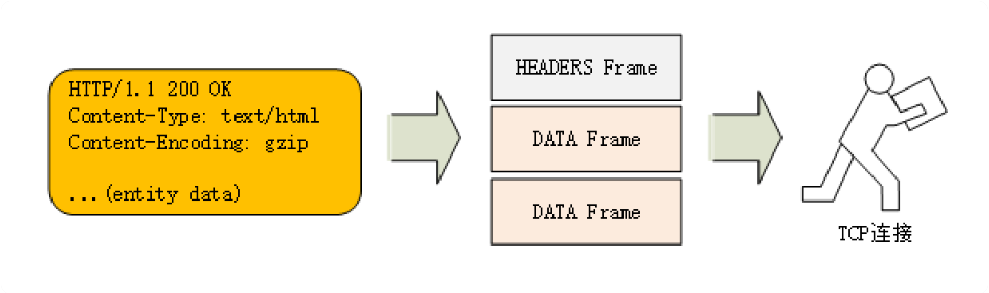
3、虚拟的“流” 和多路复用
HTTP/2 为此定义了一个“流”(Stream)的概念,它是二进制帧的双向传输序列,同一个消息往返的帧会分配一个唯一的流 ID。你可以把它想象成是一个虚拟的“数据流”,在里面流动的是一串有先后顺序的数据帧,这些数据帧按照次序组装起来就是 HTTP/1 里的请求报文和响应报文。 因为“流”是虚拟的,实际上并不存在,所以 HTTP/2 就可以在一个 TCP 连接上用“流”同时发送多个“碎片化”的消息,这就是常说的“多路复用”( Multiplexing)——多个往返通信都复用一个连接来处理。 在“流”的层面上看,消息是一些有序的“帧”序列,而在“连接”的层面上看,消息却是乱序收发的“帧”。多个请求 / 响应之间没有了顺序关系,不需要排队等待,也就不会再出现“队头阻塞”问题,降低了延迟,大幅度提高了连接的利用率。
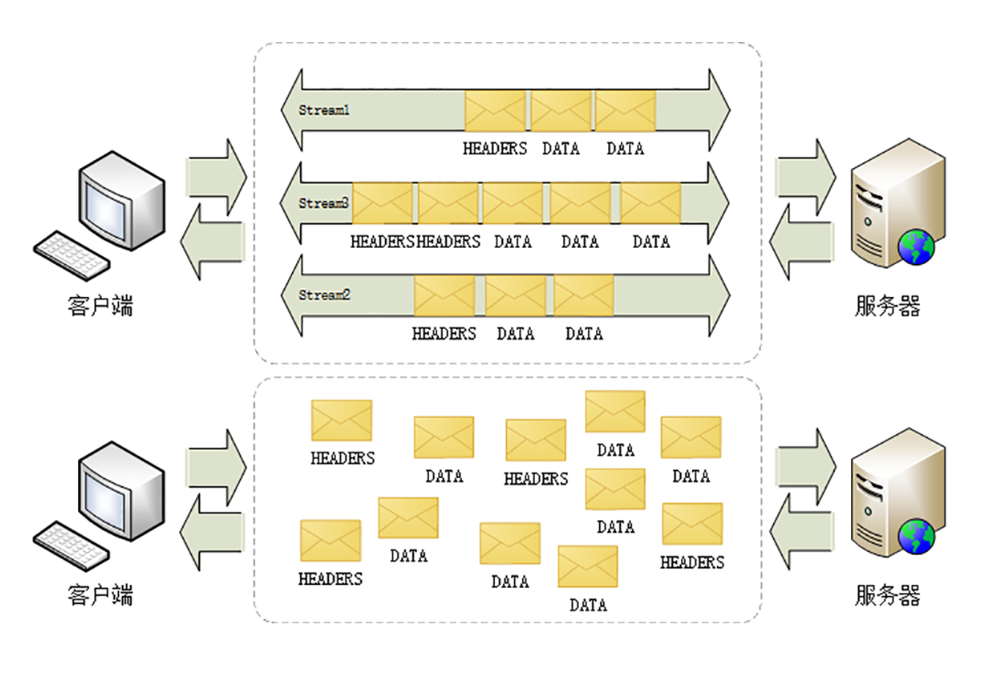
4、服务器推送 HTTP/2 还在一定程度上改变了传统的“请求 - 应答”工作模式,服务器不再是完全被动地响应请求,也可以新建“流”主动向客户端发送消息。比如,在浏览器刚请求 HTML 的时候就提前把可能会用到的 JS、CSS 文件发给客户端,减少等待的延迟,这被称为“服务器推送”(Server Push,也叫 Cache Push)。
5、安全
http2默认使用https. 为了区分“加密”和“明文”这两个不同的版本,HTTP/2 协议定义了两个字符串标识符:“h2”表示加密的 HTTP/2,“h2c”表示明文的 HTTP/2,多出的那个字母“c”的意思是“clear text”。
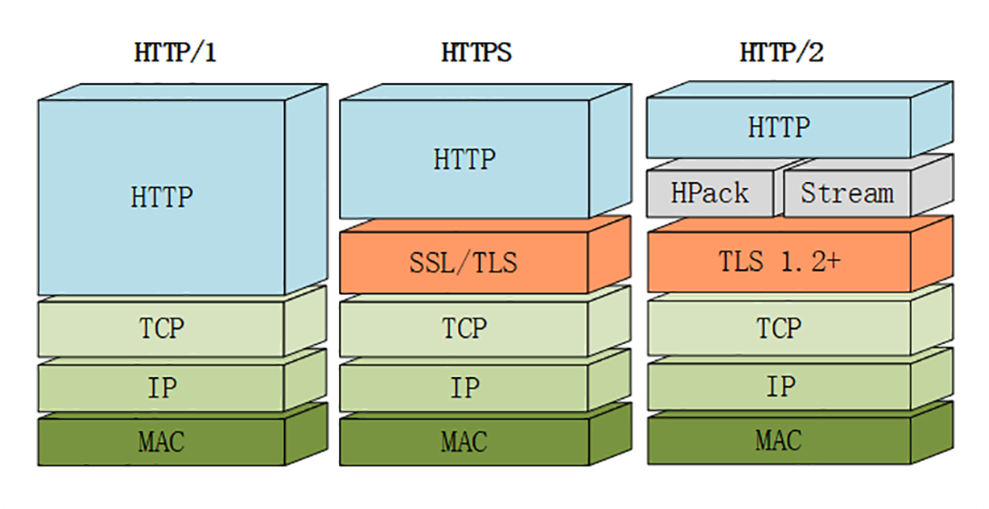
http2总结: 1、Hpack算法头部压缩,节省带宽 2、将 Header + Body的消息形式变成二进制帧 3、引入虚拟流的概念,解决应用层的对头阻塞,实现多路复用 4、增强安全:默认使用https且至少是TLS1.2以上
http3
使用基于UDP的quick协议,完全解决对头阻塞的问题,弱网环境下性能优于http2